1. What is HA
High Availability refers to a system or component designed to be available and operational for a long time. The goal is to minimize downtime and ensure that services remain accessible to hardware failures, software issues, or other disruptions.PostgreSQL High Availability (HA) in Kubernetes refers to deploying a PostgreSQL database system in a Kubernetes cluster while implementing strategies to ensure continuous availability, fault tolerance, and resilience against failures. Common strategies in a PostgreSQL HA environment involve replication and failover mechanisms to ensure constant availability.
High Availability (HA) for PostgreSQL is crucial for ensuring uninterrupted access to data and maintaining system reliability. It minimizes downtime by automatically switching to backup servers if the primary one fails. HA provides Enhanced performance and enables quick recovery from disasters. It’s vital to meet regulatory requirements, ensure business continuity, and satisfy user expectations for 24/7 availability. HA safeguards data integrity and keeps database systems resilient in dynamic environments.
High availability is essential for any enterprise that wants to protect its business against the risks caused by system outages and resultant revenue loss.
Some of the best practices to be followed while designing and implementing HA systems are:
- Data Replication, backups, and recovery
- Clustering
- Load Balancing
- Failover designs
- Geographic redundancy
- Containers and Kubernetes
2. What is PostgreSQL?
PostgreSQL is a robust and freely available Relational Database Management System (RDBMS). This open-source platform empowers users with the flexibility to handle both non-relational and relational queries using the JSON (JavaScript Object Notation) format. It is adept at efficiently managing diverse workloads, ranging from individual machines to large-scale environments.
Despite being introduced before its competitors, the platform is still regarded by experts as the most popular and reliable DBMS. It provides a wide range of extensions, enabling businesses to customize the database to suit their needs without compromising the core structure.
3. Key Features of PostgreSQL
PostgreSQL is renowned for its versatility and wide range of applications across different domains.
- Language Support: PostgreSQL provides a native procedural language called PL/PGSQL with advanced features. It also supports various programming languages and protocols like Perl, Ruby, Python, .Net, C/C++, Java, ODBC, and Go, ensuring flexibility for diverse programming needs while maintaining optimal performance.
- Open Source: Being open-source, PostgreSQL is freely available, which is a significant advantage. With over two decades of community development, it offers reliability and empowers users with unlimited data storage and the freedom to modify the source code without any extra cost.
- Performance: Performance-wise, PostgreSQL excels in simultaneous write operations without read and write locks, efficient indexing for faster searches, and support for expression and partial indexing. It also offers parallel reading queries, Just-in-time (JIT) compilation, and layered transactions, ensuring high performance and efficiency.
- Extensibility: Extensibility is another key feature of PostgreSQL. It allows users to create custom data types and write scripts in multiple programming languages without recompiling the database.
- Reliability: PostgreSQL ensures reliability through secure data storage and continuous enhancements from a proactive community of contributors.
- Load balancing: For load balancing, PostgreSQL provides standby server operation, streaming replication, replication slots, cascade replication, and synchronous replication, ensuring high availability for critical data.
- Scalability: Scalability is achieved through comprehensive support for Unicode, enabling international character sets and multi-byte encodings across multiple operating systems.
- Integrations: In terms of integrations, PostgreSQL seamlessly supports various programming languages, making it a preferred choice for developers.
- Dynamic loading: Dynamic loading allows users to integrate custom code effortlessly, enabling the swift development of cutting-edge applications while maintaining performance.
- Vendor lock-in: PostgreSQL’s open data-sharing policy fosters accessibility and mitigates the risk of vendor lock-in.
- Multiversion Concurrency Control: Its Multiversion Concurrency Control feature facilitates seamless read-and-write operations for multiple users accessing a shared database concurrently.
4. Architecture Diagram for HA
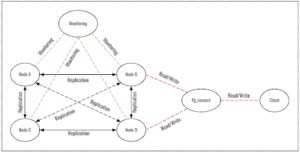
Fig 1: Architecture Diagram for HA
The image displays a computing system’s architecture diagram for High Availability (HA). It consists of four nodes labeled from Node-A to Node-D. The following describes the roles and interactions of these nodes:
- Node-A: This node acts as a primary node replicating its data to two other nodes, Node-B and Node-C. There is no direct indication that this is the master, but it’s a common convention that Node-A or the top-left node in such diagrams can be the primary or master node.
- Node-B: Receives replication data from Node-A and Node-C. It also serves read and write operations, which implies it could be a primary node or a standby primary ready to take over in case Node-A fails. In some HA configurations, both Node-A and Node-B can act as primaries in a multi-master setup.
- Node-C: Similar to Node-B, it receives replicated data from Node-A and replicates data to Node-B. It does not directly interact with the client system, suggesting it is a secondary or standby node.
- Node-D: Receives replicated data from Node-C and Node-B. It also serves read/write operations to a client computer, indicating that it could be another primary node or a secondary set to serve read operations to distribute the load.
Given the symmetrical architecture, this diagram may represent a multi-master setup, where more than one node can serve as the primary node. Otherwise, if it’s a single master configuration, Node-A or Node-B would typically be the master. Node-C and Node-D would be the secondaries, depending on the specific HA setup and failover policies.
The client computer at the right side of the diagram is connected to Nodes B and D, which suggests that these nodes are handling direct client requests.
With specific context and additional information, it’s possible to definitively state which nodes are primaries or secondaries, as HA architectures vary greatly. This diagram likely represents a generic HA setup, and the roles of the nodes can be defined by the actual configuration and replication policies set by the system administrators.
Here are some of the key benefits of using multi-master replication for PostgreSQL:
- High Availability: By eliminating a single point of failure, multi-master replication guarantees that the database remains available even if one or more master nodes experience an outage.
- Scalability: The architecture allows you to distribute workloads across multiple servers, enhancing the database’s ability to handle increased traffic and data growth.
- Improved Read Performance: Read requests can be directed to any of the nodes in the cluster, reducing the load on the master server and potentially improving overall read performance.
However, it’s important to consider some potential drawbacks of multi-master replication as well:
- Increased Complexity: Setting up and managing a multi-master replication cluster can be more complex than traditional master-slave replication.
- Data Conflicts: With multiple masters writing data concurrently, there’s a greater chance of data conflicts that require resolution strategies to maintain data consistency.
- Overall, multi-master replication is a valuable solution for organizations that require high availability, scalability, and improved read performance for their PostgreSQL deployments. But it’s essential to carefully weigh the benefits and drawbacks to determine if it fits your specific needs.
5. PostgreSQL Replication V/S PostgreSQL HA
In a master-slave replication setup, “master” refers to the primary database server that handles both read and write operations. At the same time, the “slave” serves as a replica of the master. The essential characteristic of this configuration is that the slave database operates in a read-only mode, meaning that it can only handle read queries and cannot accept write operations.
The diagram below depicts a simplified representation of a PostgreSQL High Availability (HA) architecture that leverages master-slave replication. This setup offers fault tolerance and improved database uptime in case the primary server fails.
5.1 Components of the Architecture
- Master Server: The master server acts as the core of the architecture. It handles all write requests and serves as the entire system’s primary data source.
- Slave Server(s): Slave servers, also known as replicas, are read-only copies of the master server. They continuously receive updates from the master server, enabling them to share the read workload and improve overall read performance.
5.2 How it Works
- Write Operations: When a write operation occurs, the data is first written to the master server.
- Replication: The changes are replicated to the slave server(s) asynchronously. The updates might not be immediately reflected on the agent servers but will eventually be applied.
5.3 Benefits of Master-Slave Replication for HA
- Improved Read Performance: By distributing read traffic across the master and slave servers, master-slave replication can enhance the overall read performance of your database.
- Disaster Recovery: In the event of a master server failure, a slave server can be promoted to become the new master. This minimizes downtime and ensures data availability.
5.4 Limitations of Master-Slave Replication for HA
- Single Point of Failure: The master server remains a single point of failure. If it fails, there’s a brief period of downtime while a slave is promoted to master.
- Limited Scalability for Writes: Since writes can only be processed by the master server, this architecture can become a bottleneck for write-heavy workloads.
5.5 PostgreSQL HA vs. Replication
It’s important to distinguish between PostgreSQL replication and PostgreSQL HA. This table outlines the differences between PostgreSQL Replication and PostgreSQL High Availability (HA), highlighting the broader scope and additional components involved in achieving HA compared to the more focused replication approach.
| Aspect | PostgreSQL Replication | PostgreSQL High Availability (HA) |
|---|---|---|
| Definition | The process of copying data from one PostgreSQL database server (master) to another (slave) to ensure data redundancy. | A comprehensive set of strategies and technologies designed to ensure that a PostgreSQL database remains available and functional, even during outages or failures. |
| Scope | Primarily focused on data redundancy and distribution. | Encompasses a broader range of strategies beyond replication, including failover, load balancing, backup and recovery, and disaster recovery. |
| Components | Master-slave replication is a key technique. | Includes replication, clustering, failover mechanisms, load balancers, monitoring tools, and automated recovery processes. |
| Objective | To ensure data is copied and available on multiple servers. | To maintain continuous database availability, minimize downtime, and ensure rapid recovery from failures. |
| Techniques |
|
|
| Failure Handling | Data is replicated to a slave, which can be promoted to master in case of failure (usually requiring manual intervention or additional automation tools). | Automatic failover to standby servers, continuous monitoring of server health, and automatic or semi-automatic recovery processes to minimize downtime. |
| Use Cases |
|
|
| Limitations |
|
|
| Examples | Streaming replication setup between primary and standby servers |
|
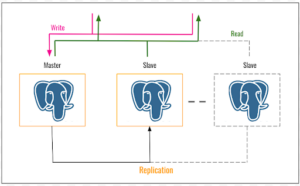
Fig 2: PostgreSQL Replication
6. Replication in PostgreSQL HA with AppZ
Setting up a high availability (HA) configuration with PostgreSQL using the AppZ stack explicitly mentions a master and slave setup with automatic switching between nodes depending on their availability.
AppZ PostgreSQL HA can support one primary and one or more secondary nodes as a Kubernetes cluster. Primary and secondary are configured to have synchronous streaming replication. The application can read/write to the primary, whereas read-only from the secondaries, which are load-balanced. Pg_auto_failover (PostgreSQL extension) sets up a keeper on each node and the monitor on a separate node. The monitor and keeper are in sync to detect any failures in the primary. Once a failure is detected, the monitor will promote any secondary to Primary and allow read/write. PgConnector is deployed as HA Proxy, which can forward the traffic to primary/secondary nodes based on the request/traffic.
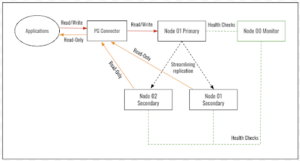
Fig 3: AppZ PostgreSQL HA Architecture
7. Purpose of PG connect in Postgres HA.
In an HA configuration using AppZ, PostgreSQL setups typically include a primary (master) node that handles writes and one or more secondary (slave) nodes that handle reads and stand ready to take over if the primary fails. Pg_connect facilitates connections to this cluster, directing write operations to the primary node and read operations to the secondary nodes, enhancing performance and reliability.
- Dynamic Query Routing Post-Failover: An essential aspect of HA is the ability to reroute queries post-failover dynamically.
- Failover Process: The failover mechanism promotes a secondary node to become the new primary node.
- Adjusting Query Routing: Pg_connect or similar proxy services then automatically adjust their routing rules to directly write queries to the new primary node, ensuring uninterrupted access to the database.
- Application Continuity: From an application’s perspective, this seamless transition ensures continuous access to the database services without manual intervention, maintaining business operations and user experience.
8. PostgreSQL HA and pg_connect: A Closer Look
8.1 Purpose of pg_connect in Postgres HA
While “pg_connect” itself simply refers to a function for establishing a connection to a PostgreSQL database in a High Availability (HA) context, it takes on a more crucial role.
Here’s why pg_connect is essential for Postgres HA:
- Maintaining Application Connectivity: During a failover event in a HA setup (where the primary server switches to a backup), applications must seamlessly reconnect to the new active server. pg_connect helps applications achieve this by understanding connection strings that can point to the HA cluster endpoint instead of a specific server.
- Managing Connection Pools: HA solutions often utilize connection pooling mechanisms to optimize resource usage. pg_connect can be integrated with these pools to ensure applications retrieve connections from the available pool in the HA cluster.
8.2 Connecting a Postgres HA with pg_connect
Here’s a breakdown of how pg_connect aids in connecting your application to a Postgres HA setup:
- HA Proxy Integration: Many HA solutions, like those built on haproxy, provide a single endpoint for the entire cluster. pg_connect can be configured to utilize this endpoint in the connection string.
- Intelligent Routing: The HA proxy monitors the health of the cluster servers. When your application connects using pg_connect, the proxy intelligently routes the connection to the currently active read/write server within the HA cluster.
- Transparent Failover: If the primary server fails, the HA proxy automatically directs subsequent connections to the new active server. Existing connections using pg_connect might experience a brief interruption, but they should automatically reconnect without requiring application code modifications.
In essence, pg_connect bridges your application and the HA cluster, ensuring seamless and reliable database connections even during server failures.
Note: While the text mentions “Pg_connector” as an image built on haproxy, it’s likely a specific implementation detail and not a commonly used term. The core concept revolves around pg_connect and HA proxy integration for managing connections in a Postgres HA environment.
9. Workflow of Postgres HA Failover with PG Auto-Failover (3 Nodes)
This scenario depicts a Postgres HA setup with three nodes:
- Node 0 – Monitor: This node acts as the dedicated watchdog, constantly monitoring the health of the other two nodes (Primary and Secondary).
- Node 1 – Primary: The initial active server handles read and write requests.
- Node 2 – Secondary: This node acts as a replica, maintaining an up-to-date database copy from the Primary.
9.1 Failover Process
- Failure Detection: The monitoring node continuously checks the health and availability of the Primary and Secondary nodes. If it detects a failure in the Primary (e.g., process crash, hardware malfunction), it triggers the failover process.
- Notification and Promotion: The monitoring node leverages PG Auto-failover (a popular third-party tool) to communicate the failure to other components. PG Auto-failover then promotes the Secondary node (Node 2) to become the new Primary.
- Routing Update: With the new Primary in place, PG Auto-failover or the underlying HA framework updates the application connection routing. This ensures that application traffic seamlessly redirects to the latest Primary server, minimizing downtime.
9.2 Importance of the Monitoring Node:
- Dedicated Monitoring: With a dedicated monitoring node, the system avoids placing extra monitoring load on the Primary or Secondary, ensuring optimal performance for both.
- Early Detection and Response: The monitoring node provides faster detection of failures in the Primary, allowing for a quicker failover process and reduced downtime.
- Improved Communication: The monitoring node acts as a central point of communication, notifying PG Auto-failover about failures and facilitating a coordinated response.
This setup consisting of three nodes, including a specialized monitoring node and PG Auto-failover, provides a resilient and automated failover mechanism for your PostgreSQL high availability (HA) environment.
10. Conclusion
Implementing PostgreSQL HA on Kubernetes provides a resilient, scalable, and manageable database solution that can withstand failures and scale according to demand. Through automatic failover, dynamic query routing, and Kubernetes’ orchestration capabilities, businesses can ensure their critical database services remain uninterrupted, meeting the demands of modern, high-availability applications. This approach not only protects against data loss and service disruption but also aligns with best practices for cloud-native development, offering a robust foundation for enterprise applications.
