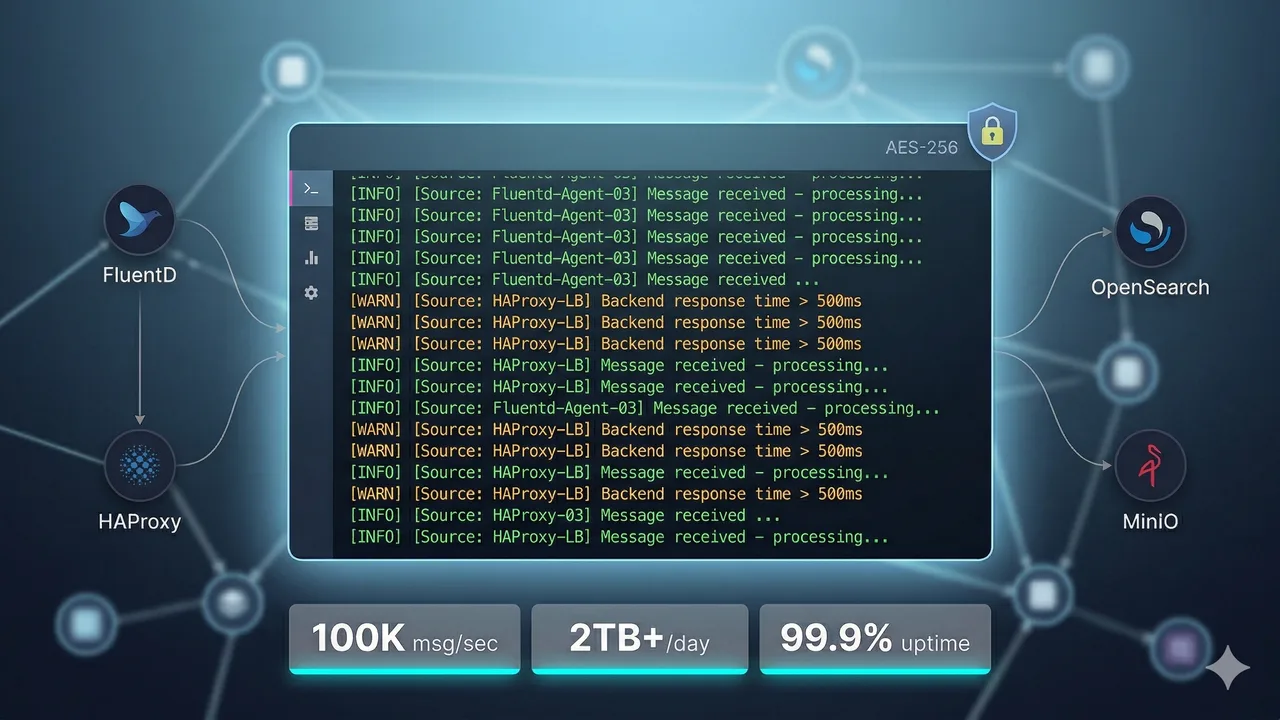
eCloudControl
DevOps, Cloud and SRE Engineering Blog
Practical guides, case studies, and deep dives on cloud infrastructure, Kubernetes, SRE, and platform engineering.
Featured Article
Why Your Data Platform Blocks Enterprise AI
Every enterprise is investing in AI. Most are hitting the same wall. The bottleneck is rarely the model — it is almost always the data infrastructure beneath it. Here is what AI-ready data engineering actually looks like, and how to get there.
- Over 80% of enterprise AI project failures trace back to poor data quality and missing pipelines, not the AI models themselves
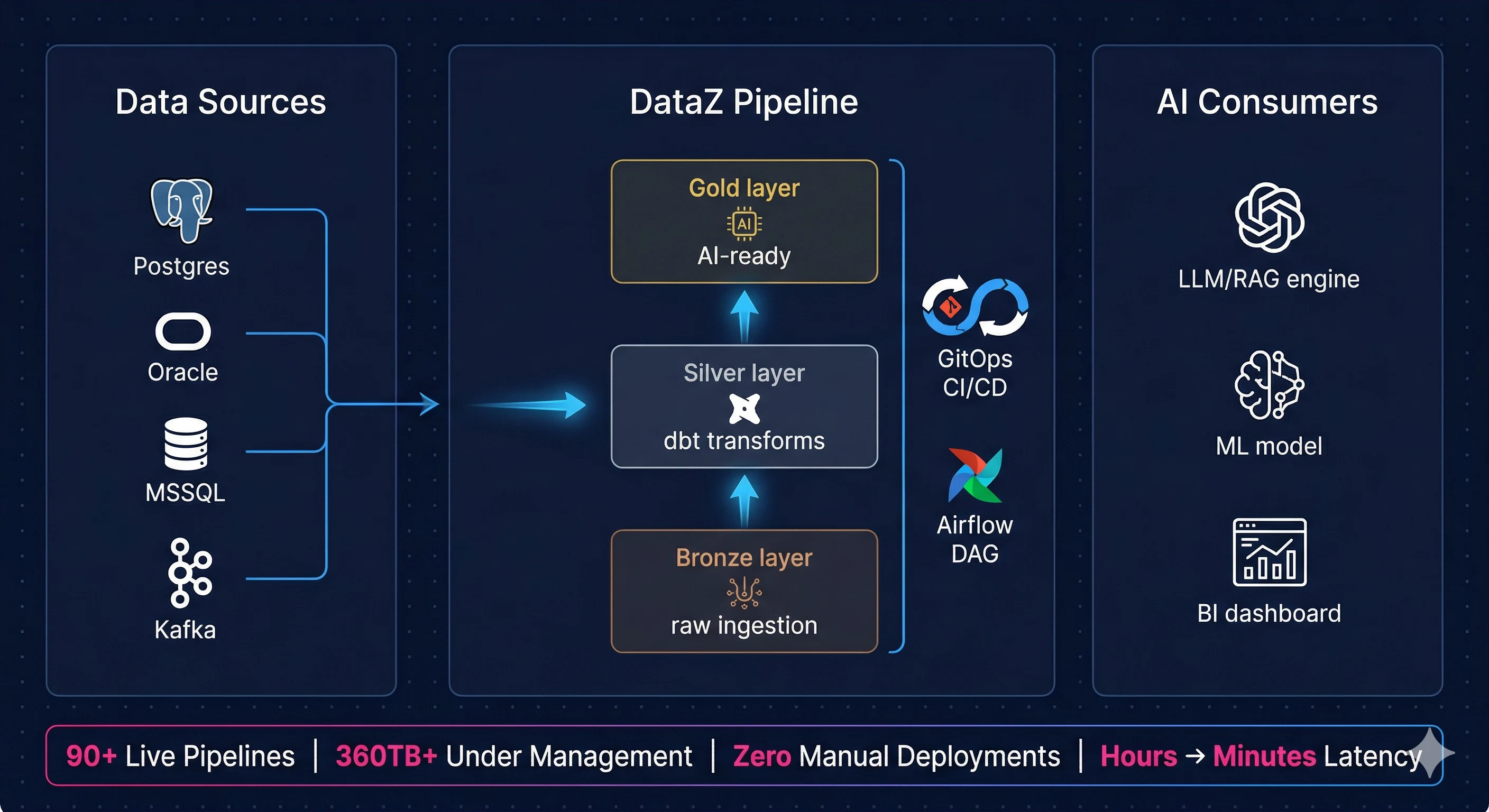
- Lakehouse architecture on Snowflake, Databricks, and Delta Lake with Apache Iceberg is now the enterprise standard
- GitOps CI/CD for data pipelines with dbt Core and automated testing is the highest-leverage operational shift a data team can make
- Real-time streaming with Apache Kafka and Debezium CDC cuts data latency from hours to minutes for production AI workloads
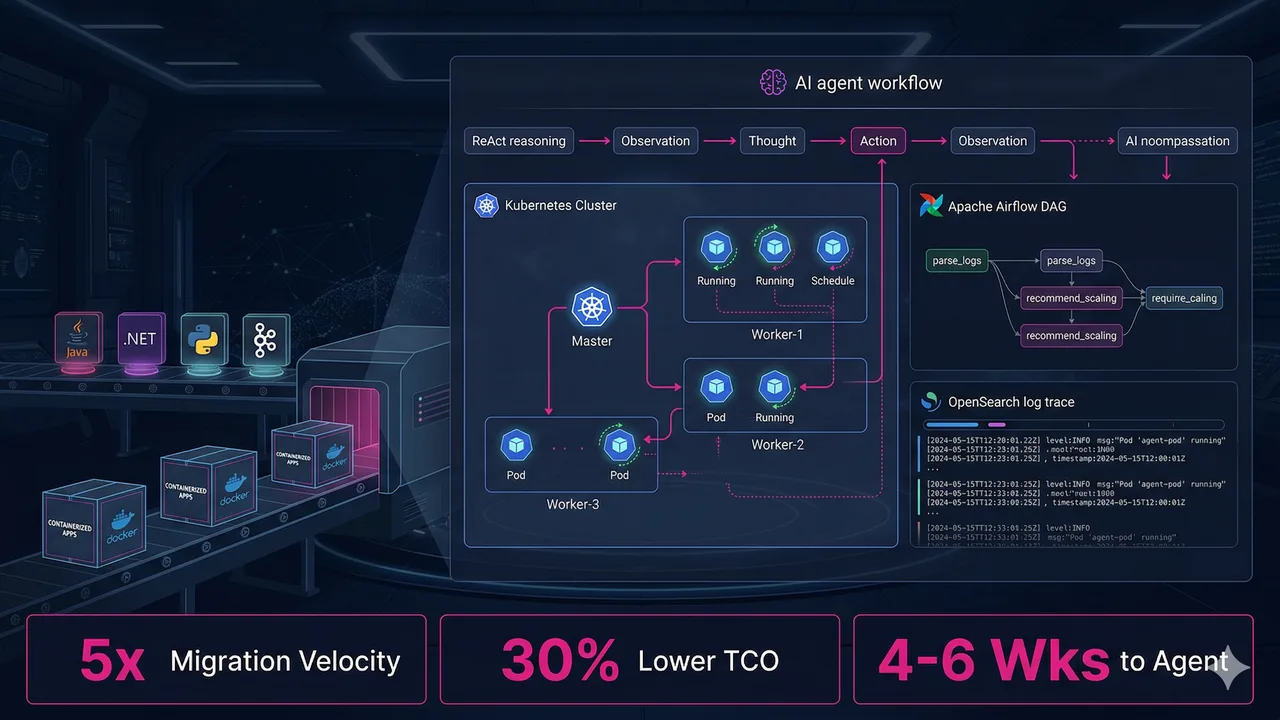
- DataZ deployed 200+ production tasks for a global financial services firm with zero manual deployments and full observability from day one
- DataZ covers the full modern data stack from Lakehouse design through AI-ready pipeline engineering across Snowflake, Databricks, Azure, and multi-cloud
Read article