Budgets are allocated. Leadership is aligned. LLM vendors have been selected. And yet, in organization after organization, the same conversation surfaces: "Our models are only as good as our data, and our data isn't ready." This is the defining challenge of enterprise AI today, and it is fundamentally a data engineering problem, not an AI one.
The Real Bottleneck in Enterprise AI
When AI programs stall, the failure point is almost never the model. It is the data layer underneath it. Data fragmented across silos. Pipelines that nobody fully understands or trusts. No observability, no lineage, governance that exists only in documentation. The models are ready. The data platform is not.
AI has made this problem impossible to defer. The organizations pulling ahead are not necessarily those with access to the best models. They are the ones with the most disciplined data platforms supporting those models. Trustworthy, governed, well-engineered data, delivered reliably and at speed, is the actual competitive advantage in 2026.
Industry Reality: Gartner estimates that over 80% of enterprise AI project failures are attributable to poor data quality, missing pipelines, or inadequate data infrastructure — not the AI models themselves. Deploying sophisticated models on an unstable data foundation does not produce AI that works in production. It produces expensive, ungoverned prototypes.
What Modern Data Engineering Actually Looks Like
The term "modern data stack" gets used loosely. In practice, it describes a specific philosophy: treat data infrastructure with the same engineering discipline applied to production software. That means version control, CI/CD, automated testing, observability, and governance built in from the start, not retrofitted later.
Lakehouse Architecture: The Foundation That Scales
The Lakehouse pattern — combining the scale and openness of a data lake with the performance and governance of a data warehouse — has become the dominant architectural choice for enterprise data platforms. Implementations on Snowflake, Databricks, and Delta Lake with open table formats like Apache Iceberg give enterprises the flexibility they need without sacrificing production reliability.
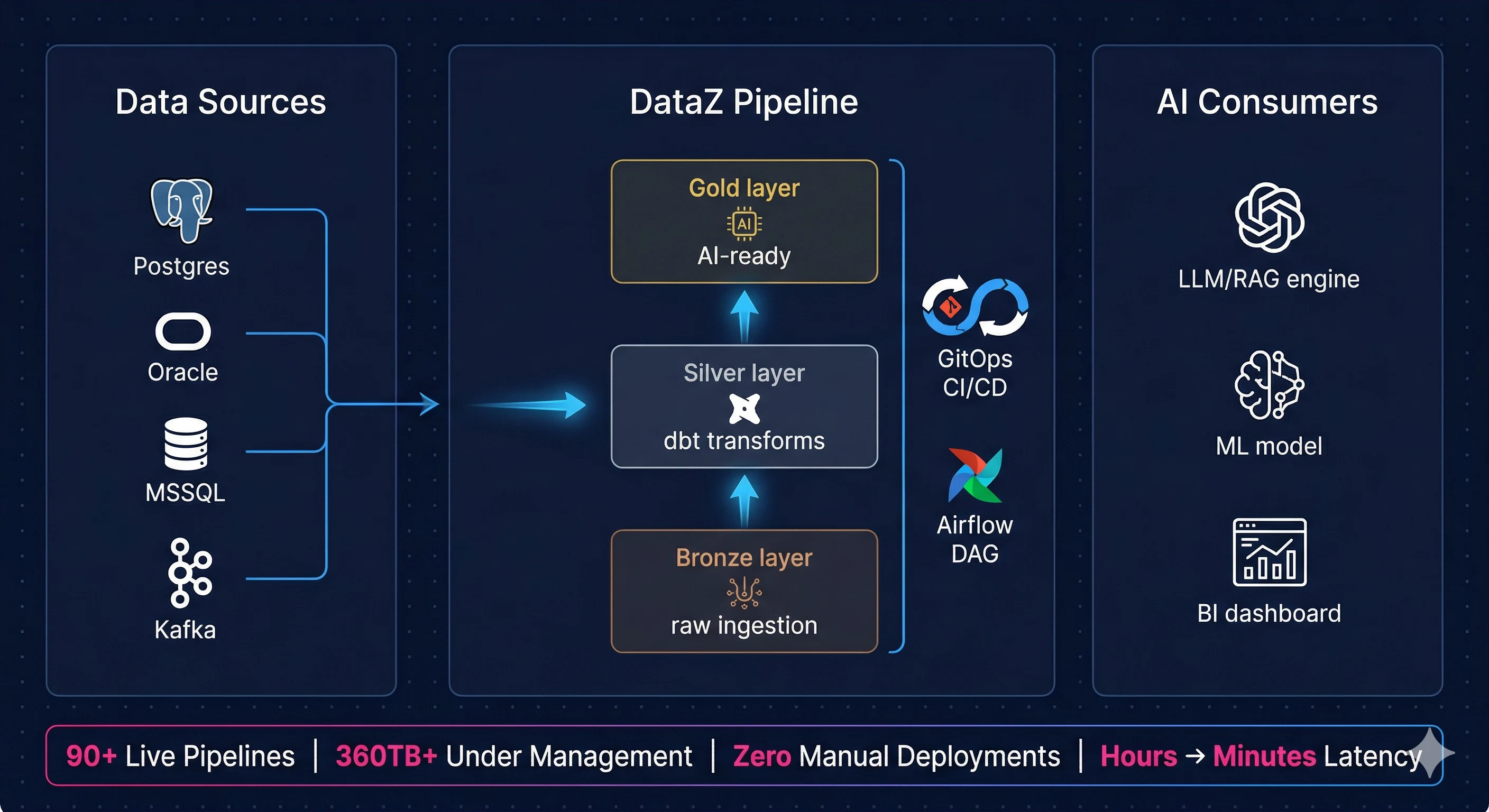
The medallion architecture (Bronze, Silver, Gold layers) sits at the heart of most mature Lakehouse implementations. Raw data lands in Bronze, gets cleaned and validated in Silver, and is promoted to business-ready in Gold. Straightforward in concept, but operationalizing this reliably, observably, and at enterprise scale is where the real engineering work lives.
Key technologies: Apache Iceberg · Delta Lake · Snowflake · Databricks · Medallion Architecture · Data Vault 2.0 · Semantic Layer · Unity Catalog
DataOps and GitOps: Engineering Discipline at the Pipeline Layer
The biggest shift in mature data organizations is treating pipelines the way software engineers treat application code. Every transformation, every DAG, every schema change goes through version control, code review, automated testing, and environment-gated promotion before it touches production.
This is DataOps in practice. GitOps-driven CI/CD using GitHub Actions, GitLab CI, or Azure DevOps, with dbt Core or dbt Cloud handling modular, tested, and documented SQL transformations. Blue/green pipeline deployments for zero-downtime rollouts. Automated schema contract validation that catches quality regressions before they ever reach a downstream consumer. The result is faster, safer delivery, with full audit trails that compliance teams can actually stand behind.
"The data teams that move fastest are not the ones with the most engineers. They are the ones with the most disciplined deployment pipelines. GitOps for data is not optional anymore."
Apache Airflow: Orchestration That Enterprises Can Trust
Apache Airflow remains the de facto standard for workflow orchestration in serious data engineering environments. DAG-based scheduling, data-aware triggers, a rich operator ecosystem, and a REST API that enables event-driven pipeline execution make it genuinely enterprise-grade. Deployed on Kubernetes (AKS, EKS) with Astronomer Cosmos for native dbt integration, Airflow handles everything from straightforward ETL to complex multi-system ML workflows within the same orchestration framework.
For AI workloads specifically, Airflow's ability to orchestrate feature engineering pipelines, model training jobs, and inference workflows alongside production data pipelines — inside a single auditable DAG framework — is a meaningful operational advantage that proprietary orchestration tools cannot match.
Key technologies: Apache Airflow · Astronomer Cosmos · DAG Factory · Data-Aware Scheduling · Kubernetes (AKS/EKS) · REST API Triggers
Real-Time Streaming and Change Data Capture
Batch pipelines are necessary. They are not sufficient for AI applications that need current context. Real-time streaming with Apache Kafka, Debezium CDC, and Azure Event Hubs enables the low-latency data delivery that production AI applications actually require.
Change Data Capture from operational databases (MSSQL, PostgreSQL, Oracle) into Snowflake Streams and Tasks eliminates the batch processing lag that has historically made operational data unsuitable for real-time inference. Moving from hours of latency to minutes of latency is often the single highest-impact infrastructure change an enterprise can make for its AI programs.
Key technologies: Apache Kafka · Debezium CDC · Azure Event Hubs · Kafka Connect · Snowflake Streams & Tasks · KSQL · Real-Time Ingestion
Data Quality, Observability, and Lineage: The Governance Layer
Untrustworthy data is worse than no data. It produces models that give confident wrong answers. Data quality must be code, not a conversation. Great Expectations, dbt tests, and schema contracts enforced in the CI/CD pipeline catch regressions before they propagate downstream.
Full pipeline observability via OpenLineage, OpenTelemetry, and Prometheus with Grafana dashboards gives operations teams real-time visibility into pipeline health. When something breaks, alerts surface immediately and the lineage trace shows exactly which downstream datasets are impacted. For enterprises running AI workloads, this transparency is not a nice-to-have. It is the difference between governed AI and ungoverned automation.
Key technologies: Great Expectations · OpenLineage · OpenTelemetry · Prometheus · Grafana · dbt Tests · Data Contracts · Schema Registry
What an AI-Ready Data Platform Actually Requires
Building for AI is not just about having clean data. It requires specific capabilities that most legacy data platforms were never designed to support.
Vector Embeddings and RAG Pipelines — LLM-powered enterprise applications depend on retrieval-augmented generation. The data platform must support vector embedding pipelines that convert enterprise knowledge into searchable, contextual representations. This is infrastructure work, not data science work.
Feature Engineering Pipelines — ML models require curated, versioned, continuously refreshed feature sets. Snowpark, Databricks Feature Store, and Azure ML integration, orchestrated via Airflow, ensures features are production-grade and fully reproducible across environments.
MLflow and Experiment Tracking — Model training, validation, and inference pipelines need the same observability as data pipelines. MLflow integration within Airflow-orchestrated workflows delivers full experiment lineage and model governance alongside data lineage.
Compliance and Security by Design — Column-level security, row-level filtering, RBAC, and SSO built into the platform architecture from day one. AI governance is only credible when the underlying data access controls are demonstrably correct and independently auditable.
Data Mesh: Scaling Governance Without Creating Bottlenecks
Centralized data platforms become bottlenecks as organizations scale. Data mesh addresses this by shifting ownership of data products to the domain teams that understand them best, while maintaining platform-level guardrails through shared infrastructure, standards, and governance.
In practice, this means implementing data contracts between producers and consumers, automated schema compatibility checks, and self-serve data product publishing — with Unity Catalog (Databricks) or Snowflake RBAC enforcing fine-grained access at scale. Domain teams can move quickly. Central governance still holds. This is the architecture that makes enterprise AI at scale operationally sustainable.
Introducing DataZ by CloudControl
DataZ is CloudControl's data engineering and DataOps practice, built specifically to help enterprises close the gap between where their data platform is today and where it needs to be to support production AI workloads.
It is not a consulting engagement that delivers a design document. It is a delivery-oriented engineering practice that brings software discipline to data — combining GitOps CI/CD, Apache Airflow orchestration, dbt transformations, real-time streaming, and full-stack observability into a unified operating model, with outcomes that are measurable, auditable, and built to scale.
DataZ covers the full modern data stack, from Lakehouse architecture design through to AI-ready pipeline engineering, with delivery experience across Snowflake, Databricks, Azure Data Factory, Postgres, MongoDB, and multi-cloud environments.
What DataZ delivers:
- Lakehouse and Modern Data Stack Architecture on Snowflake, Databricks, and Delta Lake with Apache Iceberg open table formats and full medallion architecture implementation
- GitOps CI/CD for Data with feature branch workflows, automated dbt testing, and environment-gated promotions across DEV, QA, and PROD
- Real-Time Streaming Pipelines with Apache Kafka, Debezium CDC, and Snowflake Streams reducing data latency from hours to minutes
- Full-Stack Observability with OpenLineage, Prometheus, and Grafana giving operations real-time visibility into every pipeline, every transformation, every failure
- Data Mesh Enablement with data contracts, schema registries, and domain-level data product ownership at scale
DataZ sits alongside AppZ (DevOps, DevSecOps, and SRE workflows for cloud operations) and ManageZ (24/7 infrastructure monitoring and management) as part of CloudControl's platform engineering portfolio, alongside lowtouch.ai, CloudControl's private, no-code Agentic AI platform for enterprise automation. Together, they give enterprises a coherent path from data modernization through to governed, production-grade AI automation.
A Real-World Example: Global Financial Services
A global financial services firm was running critical data workflows on ad-hoc scripts with no version control, no pipeline observability, and error-prone manual deployments. Engineering teams were firefighting daily. Their Snowflake environment had no governance, no lineage, and costs were growing with no visibility into why.
CloudControl deployed DataZ, establishing a full GitOps CI/CD pipeline for Apache Airflow and dbt Core with Astronomer Cosmos. Over 200+ production tasks across ESG, enterprise data, and trade allocation domains were onboarded within weeks. Snowflake Streams and Tasks replaced batch jobs, cutting data latency from hours to minutes. A full observability stack with OpenTelemetry, Prometheus, and Grafana gave operations real-time pipeline visibility for the first time. Blue/green deployments eliminated downtime during updates. Azure Key Vault-backed secret management and RBAC ensured every environment was secure and audit-ready from day one.
Results: 200+ tasks automated · Zero manual deployments · Data latency reduced from hours to minutes · 6+ systems integrated · PoC to production in weeks
Where to Start
For most enterprises, the right starting point is a focused DataOps maturity assessment. Not a lengthy consulting engagement, but a direct technical review of where the current data platform sits against the benchmarks of modern data engineering — specifically in the context of what it needs to support production AI workloads.
The gaps are almost always the same: no CI/CD for data pipelines, limited or no observability, ad-hoc orchestration with no audit trail, and data quality that depends on heroic individual effort rather than systematic controls. These are solvable problems. They are not novel problems. What they require is structured execution, the right tooling, and an engineering team that has delivered this before.
If your AI roadmap is stalling because the data isn't ready, the answer is not more data scientists. The answer is better data engineering.